



























Caractéristiques
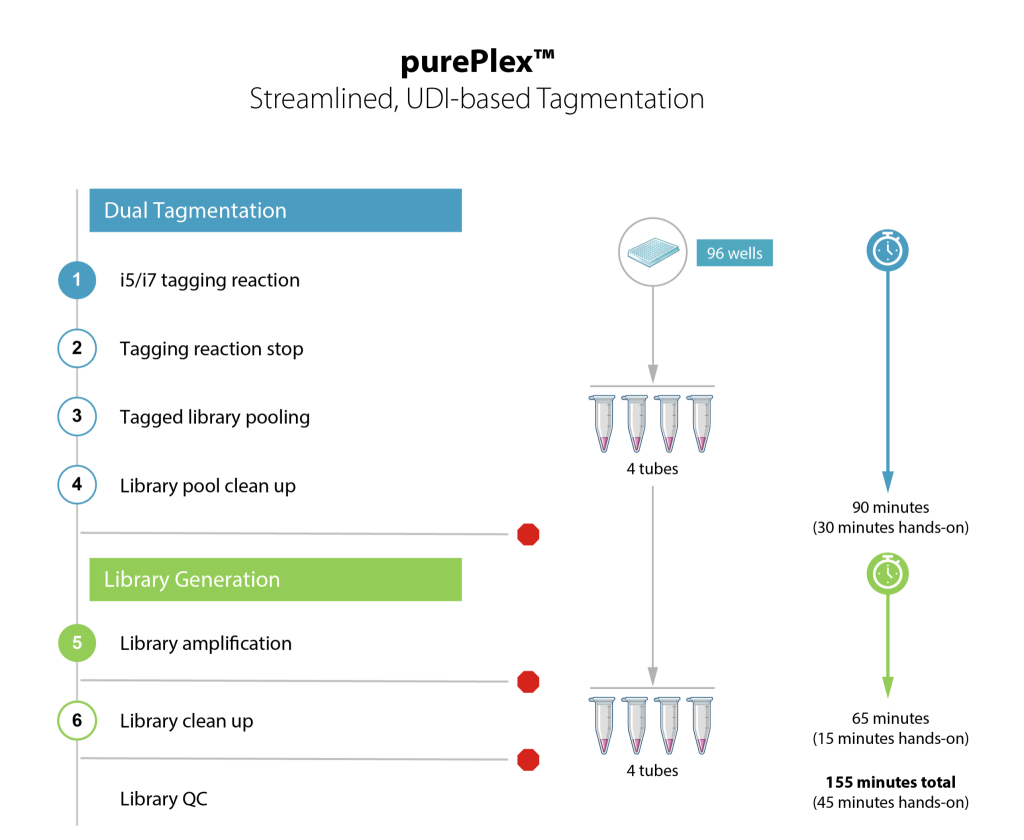
- Workflow de 2,5 heures pour 96 échantillons, 45 minutes de temps de manipulation
- La normalisation automatique réduit la charge de QC et améliore la fiabilité des données
- Pooling dès le début du workflow pour une manipulation plus aisée des échantillons
- Réduction du biais GC par rapport à d’autres méthodes basées sur la transposas
- Workflow rapide et flexible ne nécessitant pas le traitement de plaques entières
- Economies significatives en termes de coûts et de plastique
Points forts
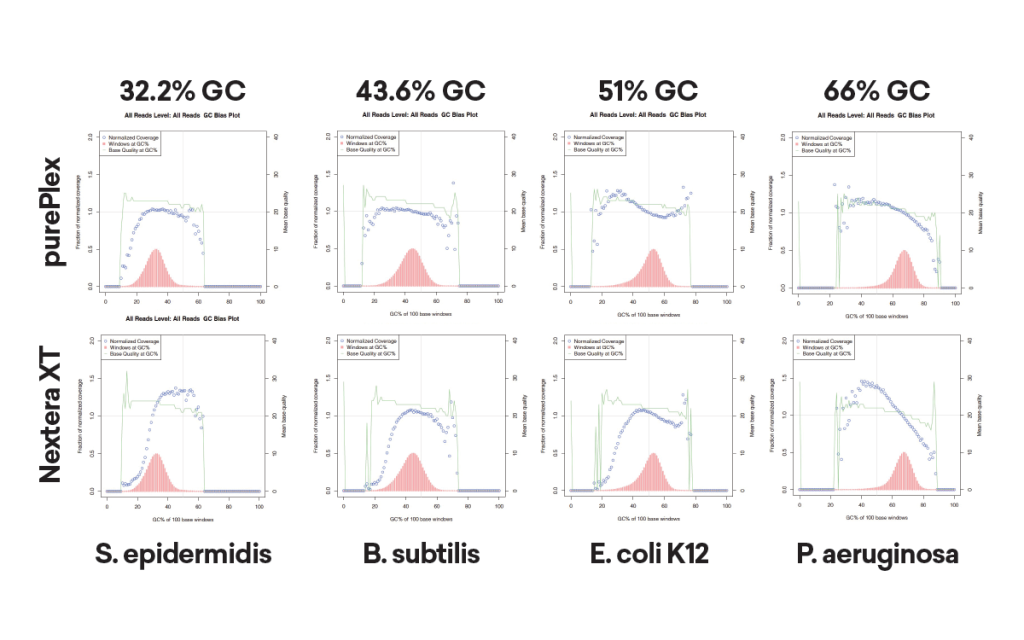
Normalisation automatique de la taille de l’insert et de la profondeur de lecture.
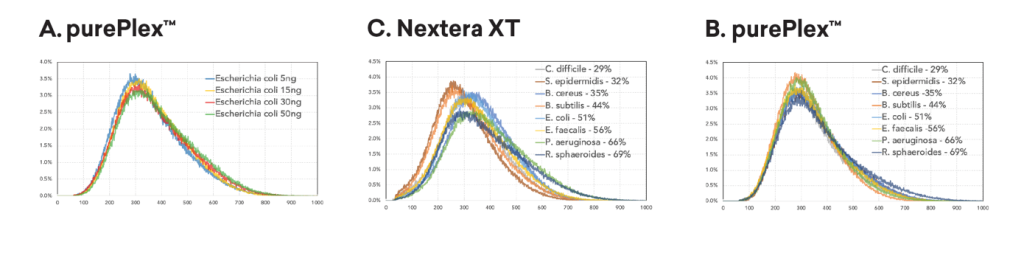
La taille des inserts dans un pool d’échantillons est cohérente quelle que soit la quantité introduite (panel A, à gauche) ou la teneur en GC (panel B, en bas à gauche).
En revanche, les librairies Nextera XT présentent des distributions de fragments variées en fonction de la teneur en GC, même après normalisation de l’échantillon d’entrée.
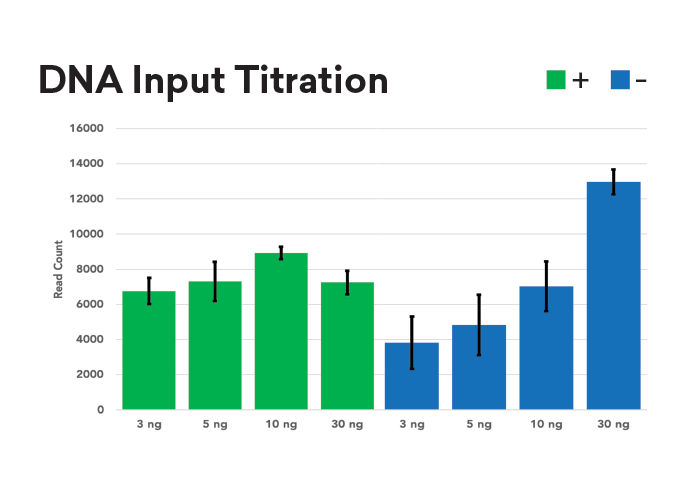
Auto-normalisation de la profondeur de lecture
Les échantillons ont été normalisés à des quantités d’input de 3, 5, 10 et 30 ng, puis ont fait l’objet d’une préparation de librairie purePlex avec (+) et sans (-) normalisation.
Les nombres de lectures pour chaque échantillon sont égaux, quelle que soit la quantité d’input, lorsque normalisation est utilisée.
En revanche, sans normalisation, le nombre de reads de l’échantillon augmente en fonction de l’input.